News came out today about the View Manager Reference Architecture papers. We have been waiting for some further technical details about scaling and best practices, so what was released and what does it mean?
First things first, where to do you get them? Well you have to
register for them. VMware have enough issues with
where to find technical documents and they have gone and introduced yet another method? Thankfully the pack is listed on the
Technical Resources page where people would naturally go looking for reference architectures; however this simply presents a link back to the registration page!
Okay, lets be clear, you are being evil VMware. Do marketing really think that someone is going to want to read these documents and not already have some form of contact with VMware that they can track and follow to pursue sales leads. Either you have already purchased it, downloaded the evaluation (which collects more information) or you obtained it from a VMware sales person. Come on, you can’t be so desperate for sales leads that you think this is going to add any real value to your pipeline. Okay, I feel better to have that off my chest.
Here are the documents and their descriptions.
- VMware View Reference Architecture - A guide to large-scale Enterprise VMware View Deployments
- Guide to Profile Virtualization - Examine traditional approaches to user profiles and discover a new way to approach user profiles in a heterogonous environment while delivering the best overall user experience.
- Windows XP Deployment Guide - This guide suggests best practices for creating Windows XP-based templates for VMware View based solutions and for preparing the templates for use with VMware View Manager 3.
- Storage Deployment Guide for VMware View - Review a detailed summary and characterization of designing and configuring the EMC Celerra NS20FC for use with VMware View.
In this “Part I” we are going to dive into the main document, the Reference Architecture.
The document consists of 36 pages detailing the infrastructure required to create a building block which can support 1,000 users. Also included is the components to integrate 5 building blocks, to support 5,000 users. Its vendor agnostic (except reference to EMC), so you can put your vendor of choice into each component, and they might bring some special additional feature to the table (but these are not considered). The first 14 pages rehash lots of features and functions of VMware View without actually giving much detail about the reference architecture, but its worth having there though.
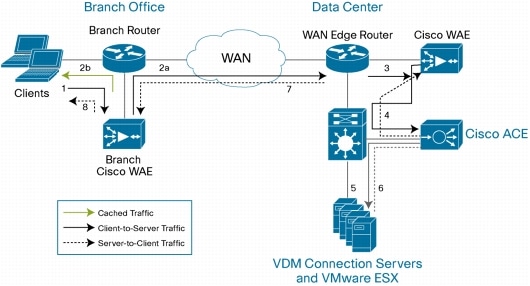
The architecture is based on large-scale, LAN-based deployment, so it does not delve into the
WAN acceleration space. Recommended bandwidth is 100-150Kbps without multimedia and latency below 150ms, so nothing new or changed here.
When describing virtual disk management the following is stated.
“Because VMware View Manager supports a variety of back ends, such as VMware View virtual desktops, Microsoft Terminal Services, Blade PCs, and ordinary PCs, it is recommended that a robust profile management solution be implemented. Profile management solutions such as RTO Virtual Profiles or Appsense can work in place of, or in conjunction with, a VMware View Composer user data disk. Profile management helps to ensure that personal settings will always be available to users who are entitled to multiple back-end resources, regardless of the system they are accessing. Profile management solutions also help to reduce logon and logoff times and to ensure profile integrity.”
This is an important point and one I will come back to in a Part II. I met today with Appsense to nut out some particular nasty VDI use cases and they have some great technology for VDI (which I started looking at back in Oct 2008 when VDM 2.0 was in Beta).
Here is what the building block looks like.
Each block consisted of a blade chassis with 16 hosts split into two clusters, A & B. Cluster A was for testing a dynamic work load of office type workers which consisted of 25 Persistent Full Clones, 225 Persistent Linked Clones and 250 Non-Persistent Linked Clones. Cluster B for a more static load of task-oriented workers and it consisted solely of 500 Non-Persistent Linked Clones.
There was one vCenter for each block of two clusters. The blades were dual quad core 2.66 Ghz with 32G of RAM. It’s a little hard to understand the networking configuration of the blades, because it’s laid out weird in the parts tables. 10G interconnects were not available when they did the test and it utalises iSCSI for the storage fabric. There is no clear detailing of the networking apart from a logical diagram and some scattered info of how it hangs together, this could be improved through further diagrams or some more details.
For the 1,000 desktop tests two VDM Connection Servers were used, for the 5,000 there was five. Desktop connections were direct hence no SSL.
All of the supporting servers (VDM, AD, SQL, vCenter etc) where virtual but resided outside of the block.
The storage was a NS20FC with a CLARiiON CX3-10F backend with 30 x 300GB 15K FC disks. It was very hard to tell but it looks like each blade enclosure was directly connected via Ethernet to the SAN. Seven Datastores were created for each cluster, which gives around 64 VMs per Datastore.
The good thing here is that these are all sensible and common components which can be achieved in the real world outside of the lab where money for things like RAM sticks is irrelevant.
Provisioning results are detailed. The 500 linked clones in Cluster B took 161 minutes, or just under 33 seconds each, that’s nice and fast. One interesting point that was highlighted is that each data store gets one replica for its clones to use and that different pools will share the same replica if they are off the same Parent version (snapshot), sweet. I knew they were copied per datastore but not that they were shared across pools.
Load testing was done with normal MS office applications plus Acrobat, IE and real time Anti-virus, performing actions for 14 hours. Each desktop had a 8Gb disk and 512Mb of RAM.
What was the result?
“1,000 users can easily be maintained by this architecture [with fast application response time] using the provided server, network, storage resources, and configuration”.
Application response times are detailed and they look fine, but there is no comparison to benchmark against.
In the performance testing neither cluster went over 50% utilization. The VM to core ration is just under 4:1 which is on the money. Given the CPU utalisation it looks like you could got to 5:1 and run around 640 machines, however more RAM may be required. The vCenter and SQL server managed fine with the load. Likewise the storage in terms of CPU and IOPS was fine with spare capacity.
So what’s missing.
Well a glaring omission is any metrics on memory utalisation. As most installations are memory rather than CPU bound it would have been interesting to see how close to the wire the memory footprint would have been? What about over commit, how much transparent pages sharing was there? Sure it’s a reference platform but they would be very helpful figures to see, certainly no less helpful than the CPU ones. Are VMware trying to hide something here? I doubt it, but it does beg the question then why not include it?
Lastly it would have been good to see a lot more configuration data, how the storage was laid out, some more of the network connectivity. Yes its trying to be vendor agnostic but if you can include VLAN ids you can include a storage design. There is a lot of this information in the other reference paper on the NS20, but people are not going to look their for high level stuff if they are not condsidering that SAN.
There you have it. In Part II we will look at some of the other documents.
Rodos